
It is no secret that data lakes are becoming more and more popular. Cloud data lakes, in particular, offer many benefits over on-premises data lakes. But what exactly is a cloud data lake? And how does it differ from an on-premises data lake? In this blog post, we’ll answer those questions and learn about how cloud and on-premises data differ in terms of scalability, security, and costs.
There are many data lake cloud services to choose from that provide a compelling alternative to traditional on-premise infrastructure. This blog will walk you through the fundamentals of cloud-based data lakes, and explain that you can’t go wrong with the big three cloud providers, so you can make informed decisions as you migrate to the cloud.
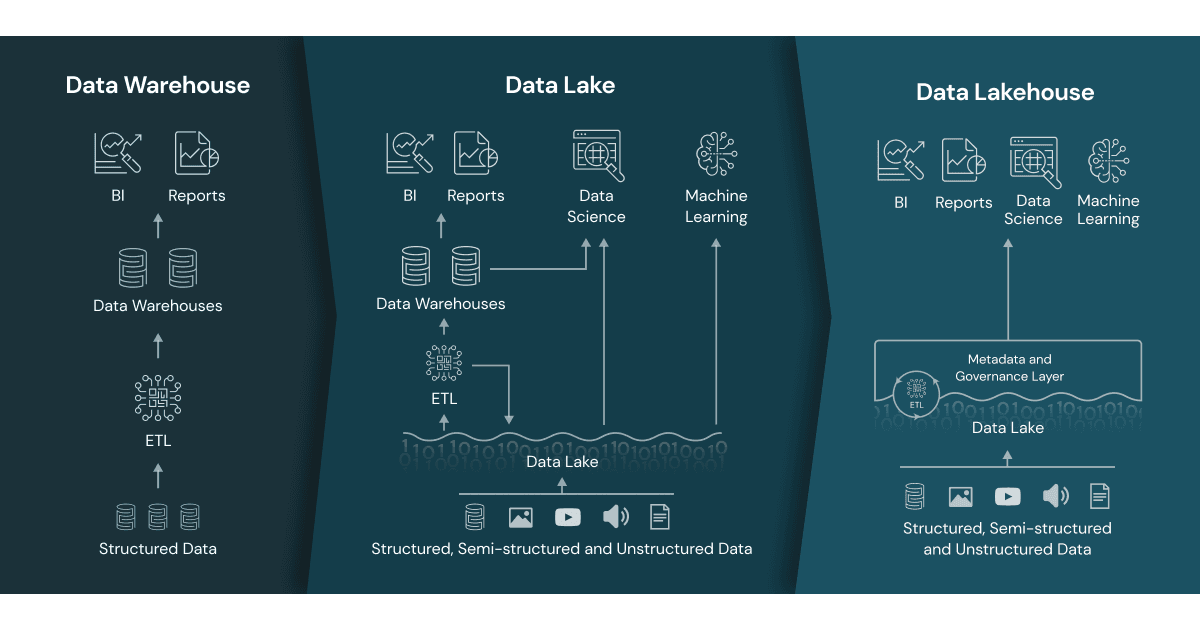
About Data Lake
Data lakes are a type of data storage repository that allows you to store large amounts of data in its native format, without the need for any kind of transformation. This makes it possible to use data lakes for a variety of different purposes, including analytics, machine learning, and even business intelligence.

The primary difference between data lakes and data warehouses is that a data lake can store both structured and unstructured data, allowing you to work with it and analyze it later. Traditional database architecture overhead would generally include lengthy ETL and data modeling when ingesting the information (to impose schema-on-write).
On the other hand, The schema-on-read data model, allows you to structure data as you retrieve it from storage. This enables organizations to store large amounts of data more easily while still providing a higher level of data analysis and exploration options.
Data lakes provide a solution to help organizations collect big data, which can be manipulated further and mined for insights by data scientists, analysts, and developers. On the other hand, data stored in a data lake is unstructured and difficult to use. To fully optimize data, it must be processed and prepared for analysis, which can be difficult for organizations, lacking extensive big data engineering resources.
Cloud Data Lake or On-Premises Data Lake?
Organizations are increasingly using cloud infrastructure-as-a-service solutions to build their data lakes, which are located in the cloud. What difficulties does on-premises setup pose for businesses, and do cloud providers provide a comprehensive solution?
Complexities with On-Premise Data Lakes
Difficulty in building data pipelines: When you develop your own on-premise infrastructure, it is a must for you to manage both the hardware infrastructure – starting up servers, orchestrating batch ETL jobs, and dealing with outages and downtime—as well as the software side, which necessitates data engineers to connect a variety of tools used to ingest, organize, pre-process and query the data stored in the lake.
Maintenance Costs: Apart from the initial investment needed to acquire servers and storage equipment, there are ongoing management and operating expenditures when running an on-premises data lake, mostly expressed in IT and engineering expenses.
Scalability: If you want to scale up your data lake to accommodate more consumers or bigger data, you’ll need to add and configure servers manually. You must keep a close eye on resource consumption, as any extra servers introduce additional maintenance and operating expenses.
Benefits of Migrating Your Data Lake to the Cloud
Emphasis on business value, not infrastructure: Use the cloud to store huge data in the cloud and get rid of the need to build and maintain infrastructure, allowing you to devote engineering resources toward innovative capabilities that may be connected to revenue.
Lower costs: You can build data pipelines more successfully with cloud-based solutions. Because the data pipeline is frequently pre-integrated, you may get a functioning solution without spending a hefty amount of time on data engineering.
Use managed services: Your cloud provider will handle scaling for your business. A few data lake cloud services like Amazon S3 and Athena, offer completely transparent scaling, which eliminates the need to add machines or manage clusters.
Latest technologies: Cloud-based data lakes update automatically and make the upgraded technology available. Additionally, new cloud services can also be added as they become available, without changing your architecture.
Reliability and availability: Your cloud provider will work to prevent service interruptions and redundant data storage on various servers. For example, Amazon S3 promises “11 nines” of durability for your data.
The Big Three Cloud Data Lake Architectures
Make things concrete for you by sharing below the data lake offerings provided by these three leading infrastructure-as-a-service providers
AWS Data Lake: Amazon Web Services provides a variety of data lake solutions that includes Amazon Simple Storage Service (Amazon S3), and DynamoDB (a NoSQL database with low latency – used for high-end data lake scenarios). Additionally, the AWS suite of tools includes a database transition service to enable the transfer of traditional on-premise data to the cloud and data lake reference implementation.
Azure Data Lake: Microsoft Azure offers a data lake architecture comprising two layers – one for storage and the other for analysis. The storage layer, known as Azure Data Lake Store (ADLS), is built on the HDFS standard, has unlimited storage capacity, and can store data in almost any format. This makes it easier to migrate existing Hadoop data with a higher promise of security.
Google Data Lake: The Google Cloud Platform (GCP) offers its own data lake to facilitate lower-cost options, suitable for data lake scenarios. GCP provides a managed Hire service as a part of Cloud Dataproc and also lets you use Google BigQuery for running high-performance queries against massive data volumes.
Drawbacks of Cloud Data Lakes
Increased Storage Costs: The main downside of transitioning your data lake to the cloud is increased storage costs. In the cloud, you pay for storage as per your needs, hour-wise. With Amazon as a cloud data lake provider, you get multiple options for data storage with variable per-hour costs. This way it is possible to optimize, however, that store will become a growing expense, given increasing data volumes.
Self-Service Analytics: A Missing Piece in Cloud Data Lake Services: The primary reason for many organizations to set up a data lake is analytics. While cloud data lakes are easy to set up and maintain, connecting the dots from data ingested to a data lake to a self-service analytics solution remains a daunting task.
With the cloud, many aspects of data infrastructure get simplified and it enables convenient managed services – but simply migrating your data to the cloud will not magically solve the challenges associated with analytics. Running your data lake in the cloud allows you to rely on secure storage by Azure and AWS which further removes the need to fiddle with traditional on-premises Hadoop clusters.
Migrate to the Cloud and Set Up Analytics with Polestar Solutions
Polestar Solutions provide an end-to-end platform for data ingestion to a data warehouse and enables standard, SQL-backed analytics, including real-time analytics. To streamline your data, professional experts at Polestar Solutions assist you in organizing the data lake in a way that enables high-performance analysis, flexibility, and security with tools like Amazon Athena.
Are you ready to get analytics set up in your data lake in real-time?